Dataset Overview

EAGLE-400K dataset composition showing diverse egocentric video understanding tasks including Epic-Kitchen, Ego4D, and PTG datasets with comprehensive annotations for activities and procedural knowledge.
The EAGLE-400K dataset comprises 400K visual instruction-tuning data from diverse sources, specifically designed to enhance egocentric video understanding. The dataset includes three main categories: General video understanding tasks that test basic scene comprehension and object recognition; Activity-specific tasks that focus on identifying and understanding human activities in egocentric settings; and Procedural knowledge tasks that require understanding of step-by-step processes and temporal sequences in egocentric videos.
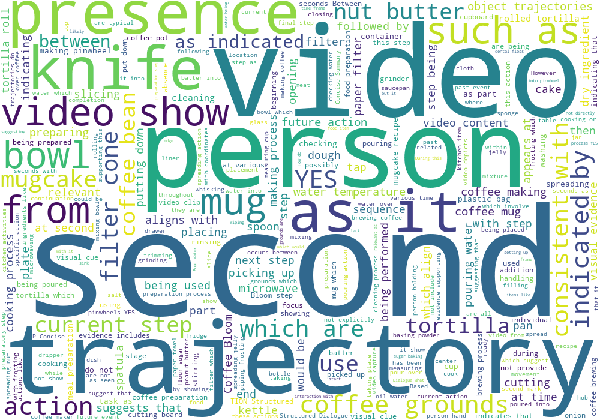
Response pattern analysis showing the language characteristics of EAGLE-400K dataset responses.
The word cloud reveals emphasis on phrases like "consistent with", "as indicated", "suggests that", and "aligns with" which demonstrate the model's analytical approach.
The responses focus on temporal relations with terms like "current step", "future action", and "making process", indicating comprehensive understanding of sequential activities and procedural knowledge in egocentric videos.
in the question prompt activates additional attention heads not triggered by the visual prompt,
suggesting that the attention heads exhibit dynamic activation based on the context—whether visual or
linguistic. This highlights their ability to adjust their function and behavior in response to changing
inputs. Further comparison between versions 1.6 and 1.5 demonstrates an improvement in image attention
across all layers in version 1.6. However, this pattern is not as evident in the 1.6 13B model. The
region token attention is omitted in 1.6 due to the more complex handling of the input image, making it
challenging to track bbox token indices. Additionally, we see that the visual prompt does not improve
the attention head’s focus on specific regions, as evidenced by comparing the first and second rows of
the heatmap.
Dataset Annotation Analysis
We conducted comprehensive analysis of the EAGLE-400K dataset across various annotation patterns and task configurations, examining key aspects:
• Instruction patterns using egocentric visual cues and procedural understanding
• Activity types spanning general, object-specific, and procedural tasks
• Response patterns focusing on temporal sequences and visual evidence
In each analysis, we examined the language patterns and annotation quality to ensure comprehensive egocentric video understanding capabilities.

Dataset annotation showcases highlighting the instruction patterns used in EAGLE-400K. The word frequency analysis reveals detailed focus on describing and understanding kitchen activities, with emphasis on sequential and procedural aspects. Key terms like "video", "describe", and "current step" demonstrate the dataset's comprehensive approach to egocentric video understanding.
Evaluation Metrics
Based on our observations, we propose an enhanced metric to more effectively capture attention head behavior
across different datasets. Specifically, we recommend not only using attention weights but also
incorporating a concentration score as a complementary dimension. This concentration score quantifies how
narrowly or broadly a model head focuses on particular regions within an image as it processes each layer.
Together, these metrics form a two-dimensional representation that offers a more comprehensive view of the
model’s attention patterns.
The evaluation framework considers both quantitative metrics and qualitative assessments. Quantitative measures include task-specific accuracy scores, temporal consistency metrics, and object interaction recognition rates. Qualitative analysis focuses on the semantic coherence of generated descriptions and the accuracy of procedural step identification.
EAGLE demonstrates superior performance across all evaluation dimensions compared to existing multimodal large language models. The model shows particular strength in understanding temporal sequences and identifying procedural knowledge, which are critical aspects of egocentric video understanding. This comprehensive evaluation validates EAGLE's effectiveness as a specialized tool for egocentric video analysis.
Qualitative Results
We present comprehensive qualitative results showcasing EAGLE's superior performance across various egocentric video understanding tasks. Our analysis demonstrates that EAGLE accurately captures the sequence of events and provides comprehensive, specific descriptions of activities, detailing each action along with the probable setting and context.
The qualitative evaluation reveals several key strengths of EAGLE:
- Temporal Understanding: EAGLE excels in understanding the sequential nature of activities and can accurately describe step-by-step processes
- Object Interaction Recognition: The model demonstrates superior ability to identify and describe object manipulations and hand-object interactions
- Contextual Awareness: EAGLE provides contextually appropriate descriptions that reflect the egocentric perspective and environment
- Procedural Knowledge: The model shows strong understanding of procedural tasks and can generate coherent descriptions of complex activities
Compared to other multimodal models, EAGLE maintains narrative consistency and provides logical sequences without unnecessary elaboration, making it particularly effective for egocentric video understanding applications.
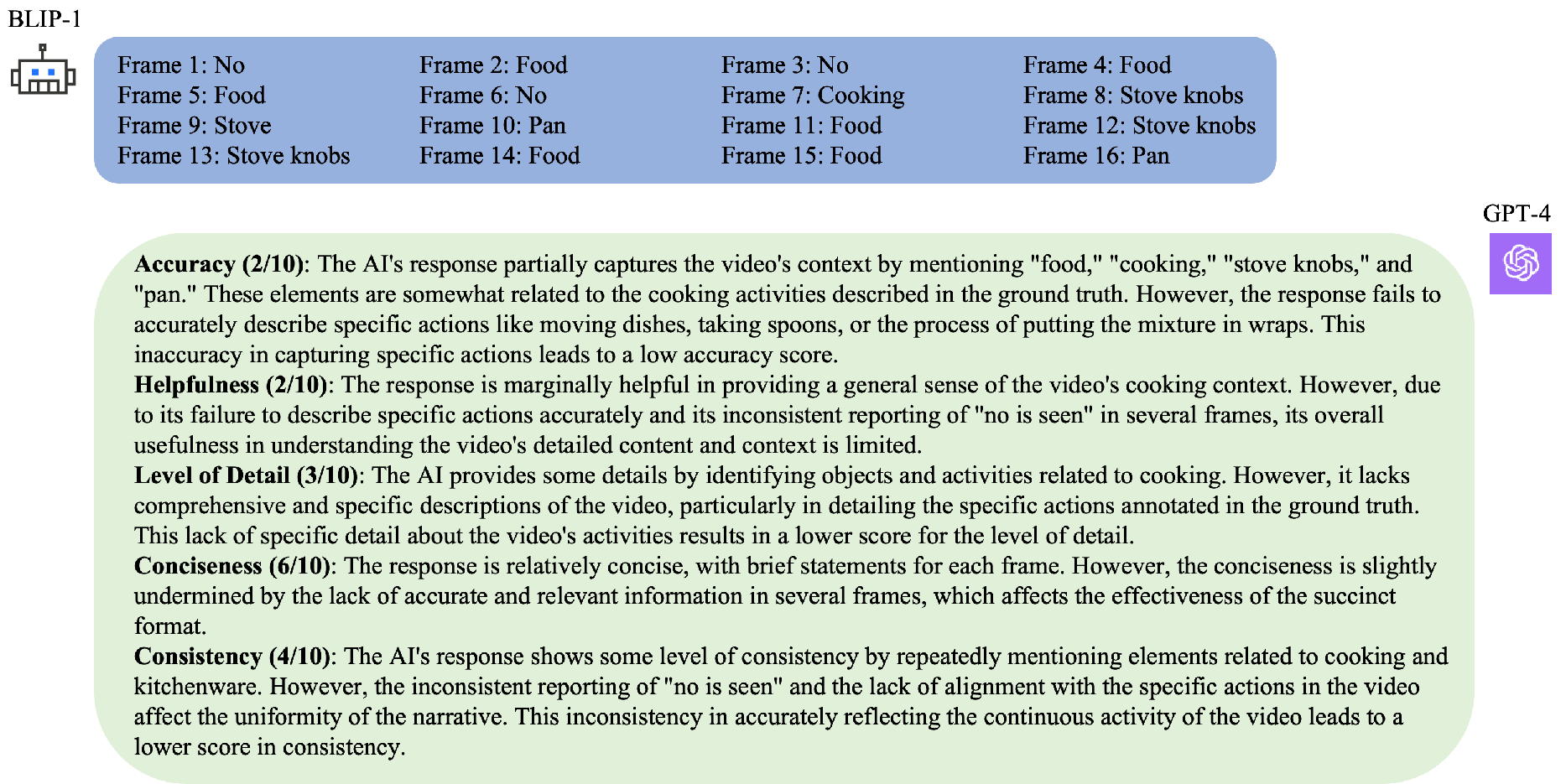
Model Comparison Results
Visual comparison of EAGLE against other state-of-the-art multimodal models on egocentric video understanding tasks. The following images demonstrate the superior performance of EAGLE in understanding and describing egocentric video content.
The comparison results demonstrate EAGLE's superior capability in understanding egocentric video content, providing more accurate and contextually appropriate descriptions compared to existing multimodal large language models.
Citation
If you found this work is useful in your own research, please considering citing the following.
View on ACM Digital Library
@inproceedings{bi2024eagle,
title={EAGLE: Egocentric AGgregated Language-video Engine},
author={Bi, Jing and Tang, Yunlong and Song, Luchuan and Vosoughi, Ali and Nguyen, Nguyen and Xu, Chenliang},
booktitle={Proceedings of the 32nd ACM International Conference on Multimedia},
pages={1682--1691},
year={2024},
publisher={Association for Computing Machinery},
address={New York, NY, USA},
url={https://dl.acm.org/doi/10.1145/3664647.3681618},
doi={10.1145/3664647.3681618}
}